Squirrel - Archive webpages so I can find them again

I created a thing that lets me save webpage contents in a smart way. I know, there are a million bookmark managers and web archivers out there, but this one is for me.
The Motivation
From Pinboard:
Do you half-remember interesting things you saw online six months ago, but struggle to find them in a search engine?
Yes, yes, a hundred times yes. This happens to me all the time. Searching my history doesn’t work because usually the keywords I remember are not in the title. Google et al. aren’t much help either.
I want a way to have the contents of the pages I visit be searchable, in a smart way.
My Requirements
1. Minimal friction to saving content
If I need to go through an entire workflow or remember some specific key combinations, I’m probably not going to use it. I want this to become a subconscious action whenever I finish reading something interesting.
Pinboard’s javascript bookmarklet is very good, but unfortunately I then need to manually add tags and a description. I mean, I don’t have to, but the bookmark is significantly less useful if I don’t.
I used the Obsidian Web Clipper for a while, and it was actually very good. The article text is saved in a new note, and tags and summaries are extracted from the page’s metadata if they exist. But, and I know this is a nitpick, it takes a few steps each time:
- Click the button
- Click “Add to Obsidian”
- Say “Yes I want to allow this site to to open Obsidian”
- Obsidian opens automatically with the new note
- Navigate back to the browser, to continue what I was doing
Every time. It’s friction.
2. Easy to run a text search across the full text
Titles and URLs are not enough. I want to expose the full article text to search, too.
Pinboard again, only allows me to search titles + manual summaries + bookmarks. I can pay $39 a year to enable full text search, but that’s kind of expensive and leads to the next point:
3. Not expensive
I mean, a couple of dollars a month isn’t that much. But they add up. This seems like the kind of problem that I, a non-power user, should be able to solve pretty cheaply.
Tangentially, I also really liked the idea behind Browser Parrot, which seems to have been replaced by Browser Gopher. It automatically saves every page from your browser history, and can extract the full text.
The problem with this was that it ended up using lots of CPU, and the archive took up a lot of space, too. I think that in practice, 90% of the pages I visit are not worth saving.
Other things that aren’t needed but might be nice
-
Some kind of tagging system (minimum friction of course) so that I can link related information and re-discover old items.
-
An accessible format to save the data. I prefer plain text to a database, because I can browse and open text files from Finder, or use them later for whatever I need.
Would a database be more byte-efficient and make searching faster? Maybe. But since I’m not going to be saving millions of files, it probably will not make much of a difference.
Based on the above, my solution
1. Put any webpage I want to save into a text file
I set up a Shortcut to grab Safari’s URL and add it to a text file urls.txt, which lives on my iCloud drive.
2. Run a script that periodically looks at urls.txt and processes new items
Setting a cron task to run this script once per day is fine. The text file is wiped after each run, and URLs that failed for some reason are saved to a separate file.
3. Access the URL to save the title and article text
Python libraries can do this easily. There is a lot of optimization that could be done to check for errors and edge cases, but as a personal project I don’t need it to be bullet-proof. Just a simple grab and dump.
4. Use ChatGPT to generate tags and a short summary automatically
This sort of thing is what AI was born to do. Having an automatic tagging system is such a luxury, and doing it directly through the API is dirt-cheap.
5. Package into a text file, and output to a local folder
Now I have a single folder on my hard drive that holds all of the articles that I thought were worth reading.
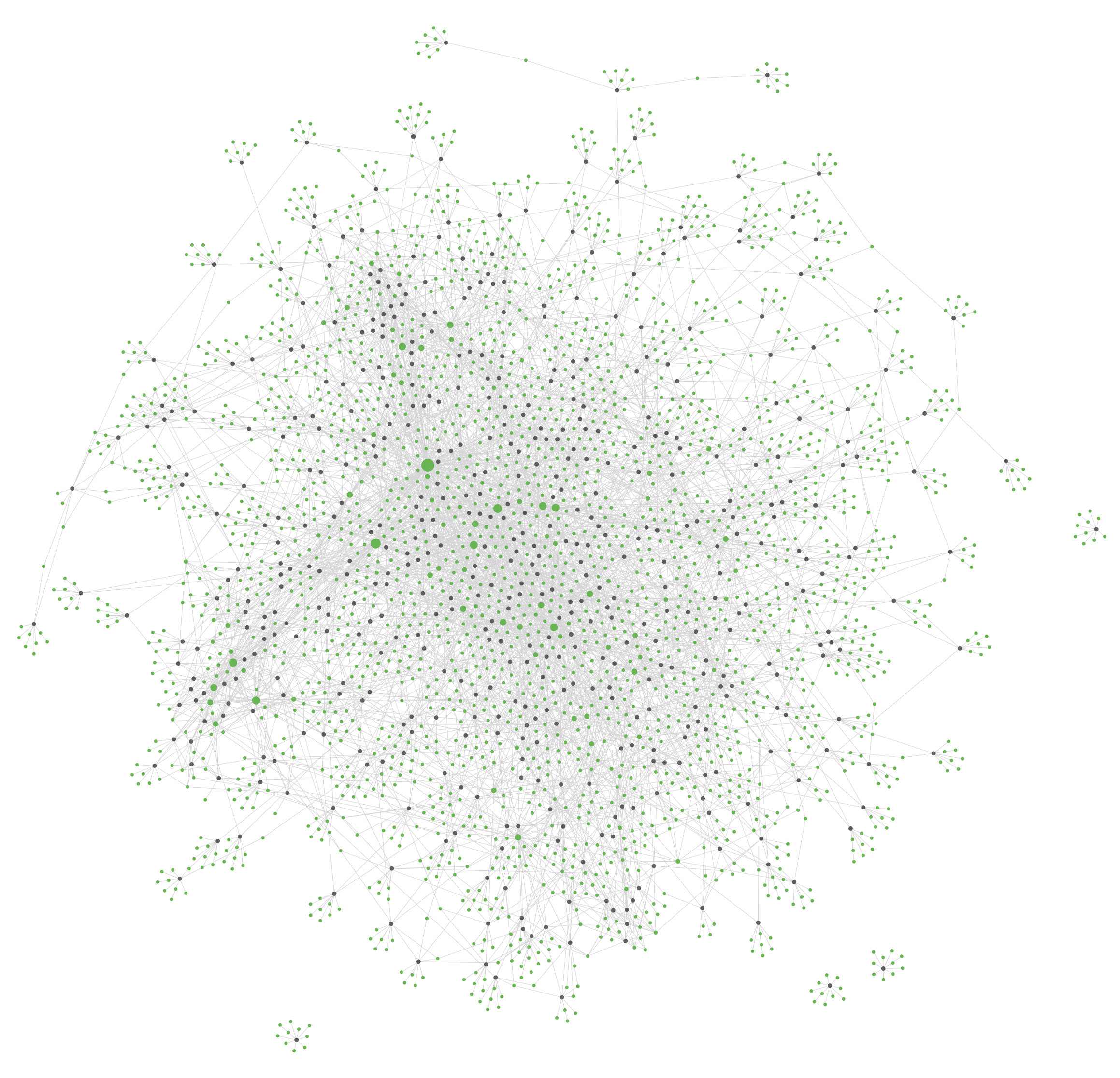
6. Open the folder as an Obsidian Vault
Searching the article contents is very fast, and I can use graph view to explore tags. I can probably do a lot to make it more useful, but for now it’s pretty.
Bonus
It also was super easy to set up an edge case for YouTube videos. Instead of grabbing the page body’s text, it instead uses the YouTube API to grab transcripts from the video. This is turning out to be a great way in general to extract information from YouTube and make it accessible to me later.
The Script
Is on Github
My intention is not to promote this for wide use, but you can feel free to fork it if you think it might work for you.
My archive now
I went through the bookmarks I had saved in various places and ran them all through this script. After pruning dead links, I had about 500 articles saved over the course of 17 years. My most used tags are:
- Technology
- Innovation
- Design
- Sustainability
- Environment
- Development
- AI
- Community
- Creativity
- Javascript
Sustainability and Environment were a surprise. I guess that when I read articles about those topics, I feel compelled to save them?
Did you like this post, or have any thoughts to share? Please send me an email!